CAPTRA: CAtegory-level Pose Tracking for Rigid and Articulated Objects from Point Clouds
ICCV 2021(Oral)
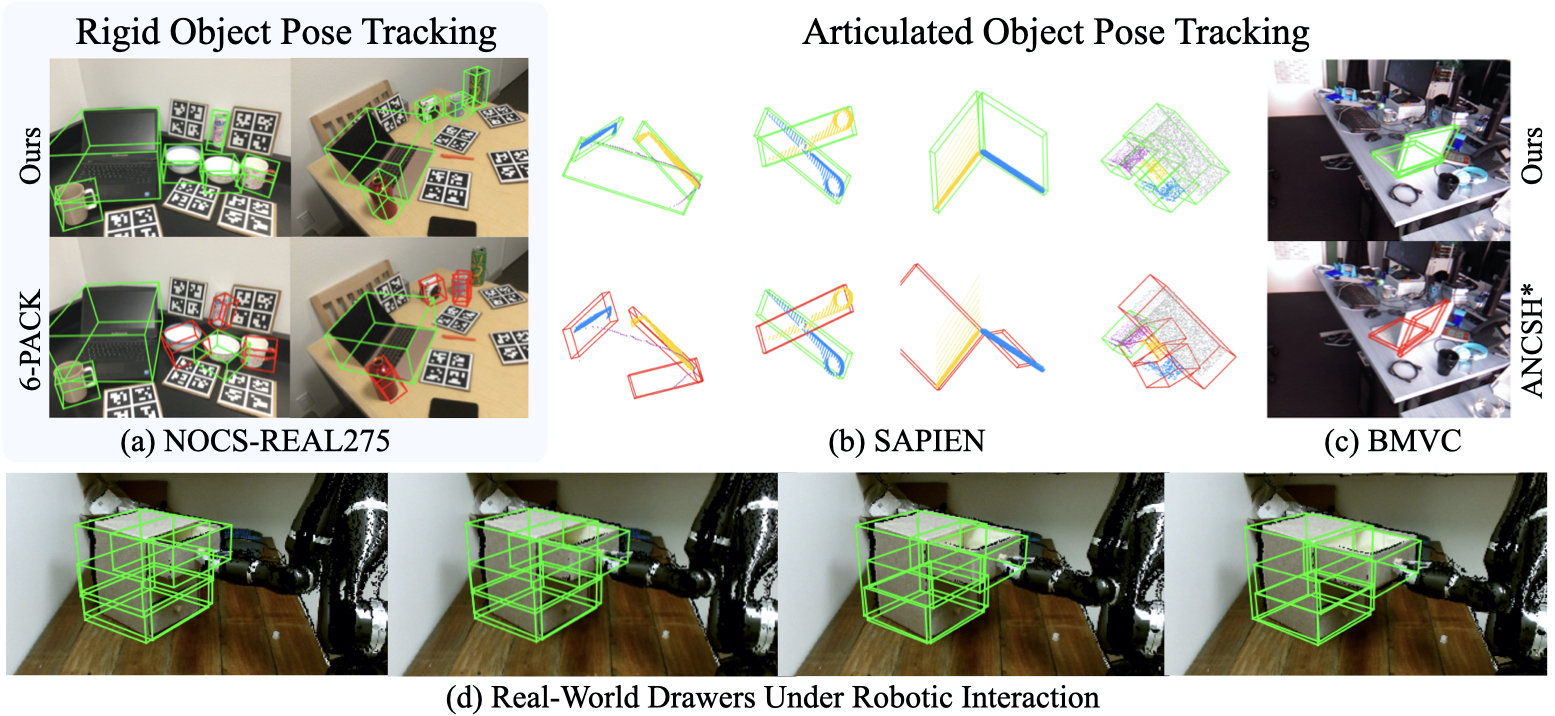
Figure 1: Our method tracks 9DoF category-level poses (3D rotation, 3D translation, and 3D size) of novel rigid objects as well as parts in articulated objects from live point cloud streams. We demonstrate: (a) our method can reliably track rigid object poses from the challenging NOCS-REAL275 dataset; (b) our method can perfectly track articulated objects with big global and articulated motions from the SAPIEN datasets; (c)(d) trained only on SAPIEN, our model can directly generalize to novel real laptops from BMVC dataset, and novel real drawers under robotic interaction. In all cases, our method significantly outperforms the previous state-of-the-arts and baselines. Here we visualize the estimated 9DoF poses as 3D bounding boxes: green boxes indicate in tracking whereas red boxes indicate off tracking.
Video
Abstract
In this work, we tackle the problem of category-level online pose tracking of objects from point cloud sequences. For the first time, we propose a unified framework that can handle 9DoF pose tracking for novel rigid object instances as well as per-part pose tracking for articulated objects from known categories. Here the 9DoF pose, comprising 6D pose and 3D size, is equivalent to a 3D amodal bounding box representation with free 6D pose. Given the depth point cloud at the current frame and the estimated pose from the last frame, our novel end-to-end pipeline learns to accurately update the pose. Our pipeline is composed of three modules: 1) a pose canonicalization module that normalizes the pose of the input depth point cloud; 2) RotationNet, a module that directly regresses small interframe delta rotations; and 3) CoordinateNet, a module that predicts the normalized coordinates and segmentation, enabling analytical computation of the 3D size and translation. Leveraging the small pose regime in the pose-canonicalized point clouds, our method integrates the best of both worlds by combining dense coordinate prediction and direct rotation regression, thus yielding an end-to-end differentiable pipeline optimized for 9DoF pose accuracy (without using non-differentiable RANSAC). Our extensive experiments demonstrate that our method achieves new state-of-the-art performance on category-level rigid object pose (NOCS-REAL275) and articulated object pose benchmarks (SAPIEN, BMVC) at the fastest FPS ~12.
Method Overview
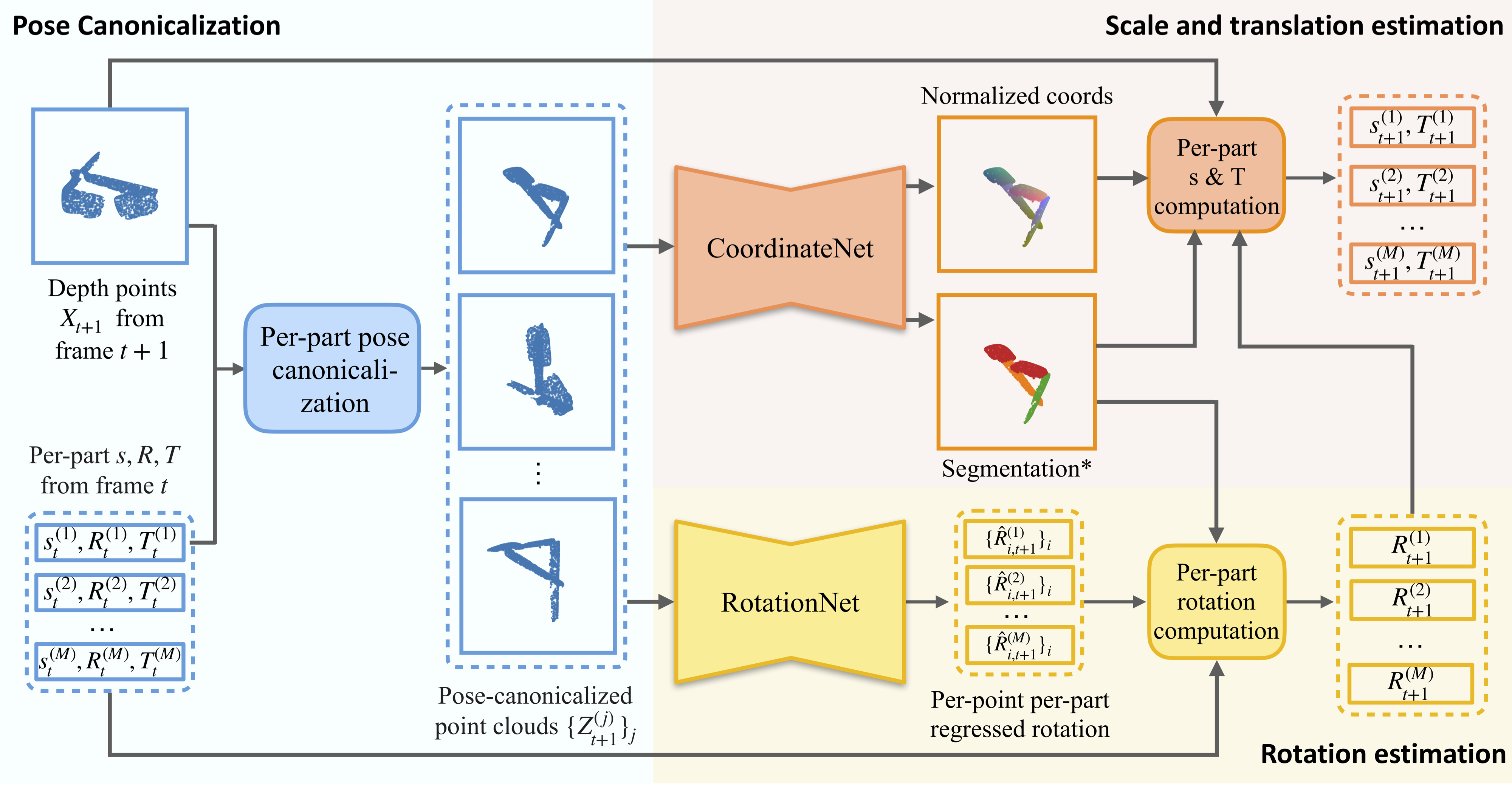
Figure 2: Our end-to-end differentiable pose tracking pipeline takes as inputs a depth point cloud of an M-part object along with its per-part scales, rotations, and translations estimated from the last frame. We first adopt per-part pose canonicalization to transform the depth points using the inverse estimated pose and generate M pose canonicalized point clouds. The canonicalized point clouds will be fed into RotationNet for per-part rotation estimation, as well as CoordinateNet for part segmentation and normalized coordinate predictions, which are used to compute the updated scales and translations. When RGB images are available, segmentation can be replaced by the results from the off-the-shelf image detectors for better accuracy. Such a pipeline can be naturally adapted to rigid objects when M=1.
Results
Rigid Object Pose Tracking
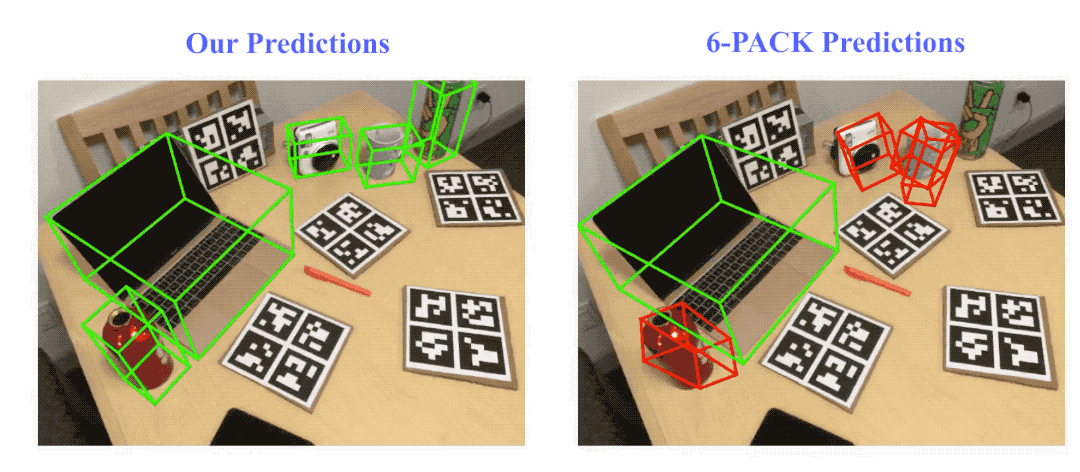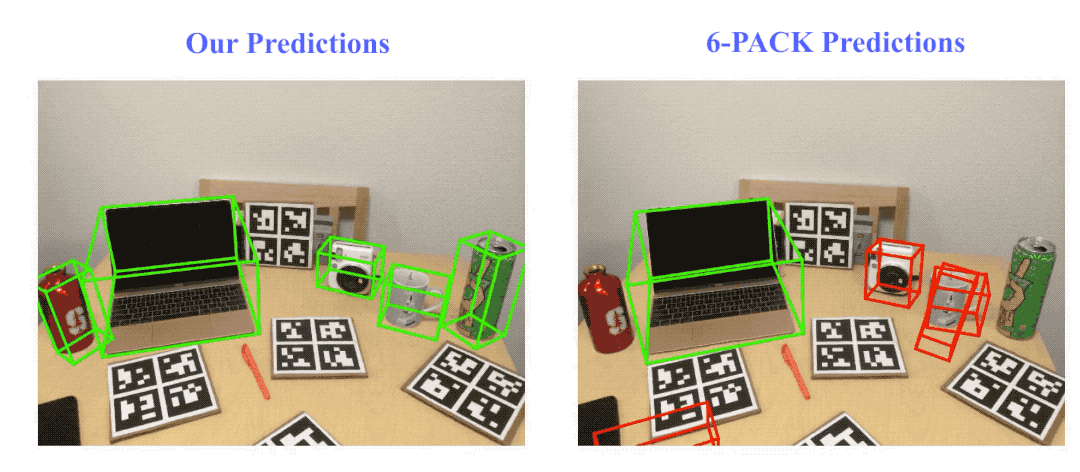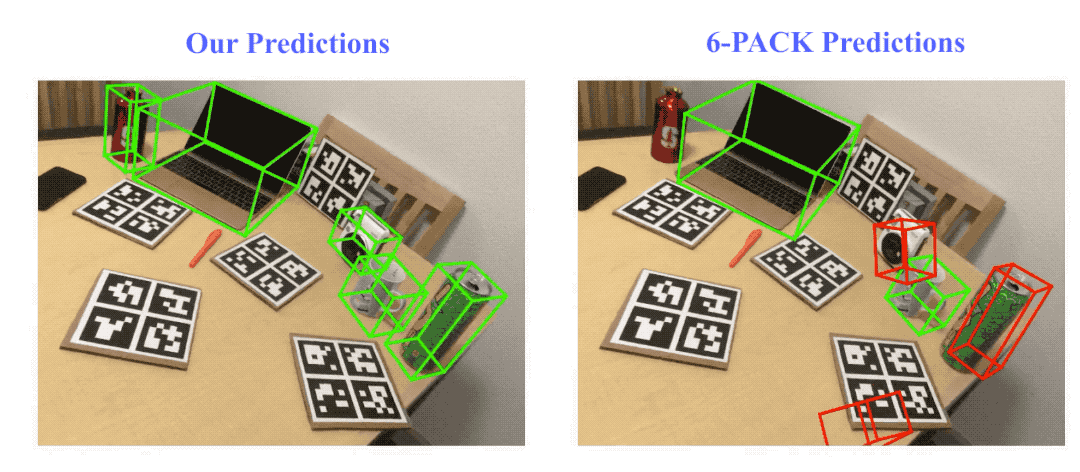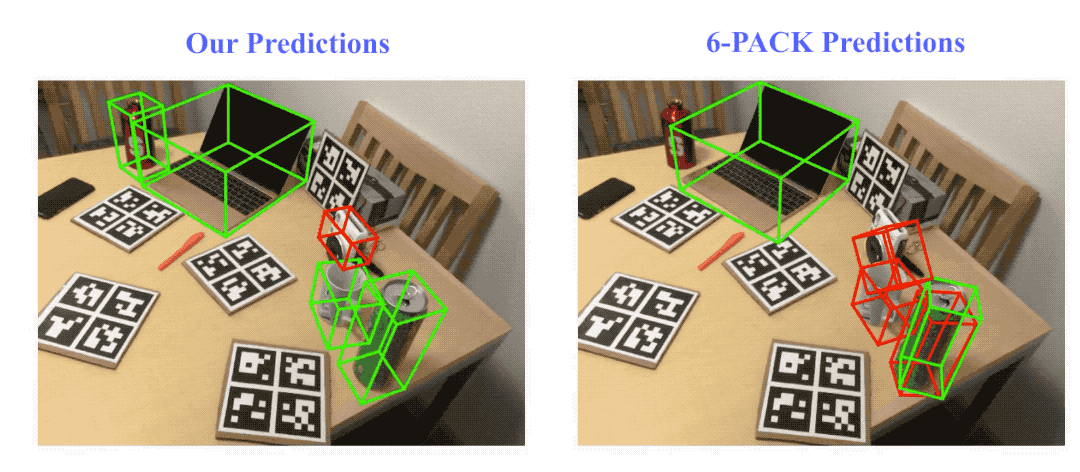
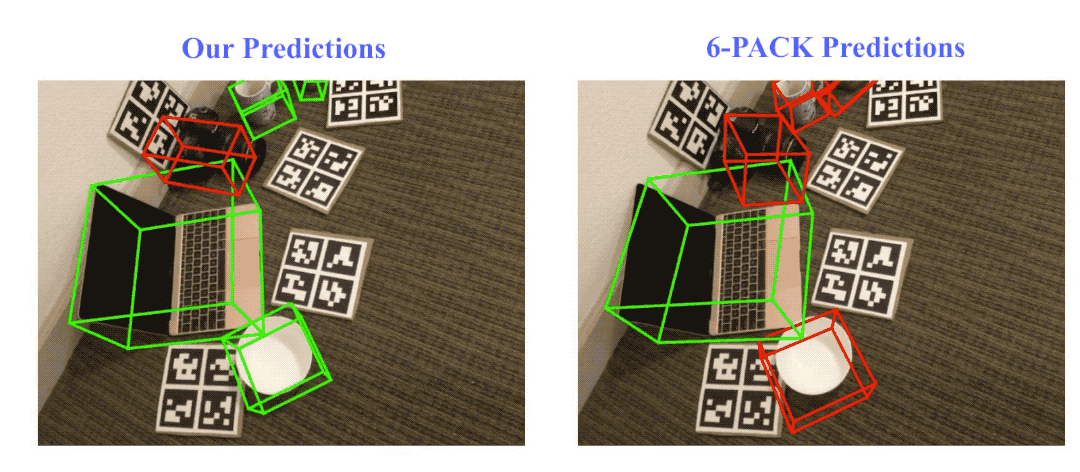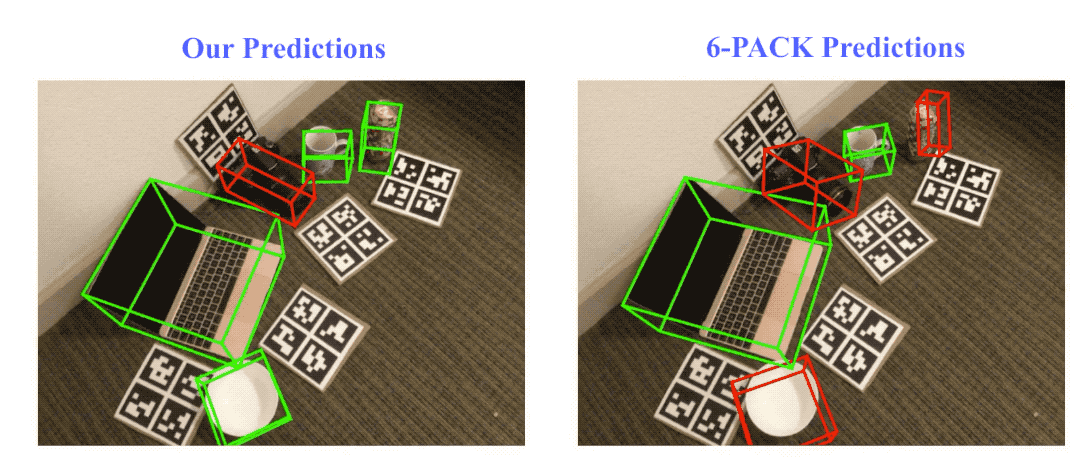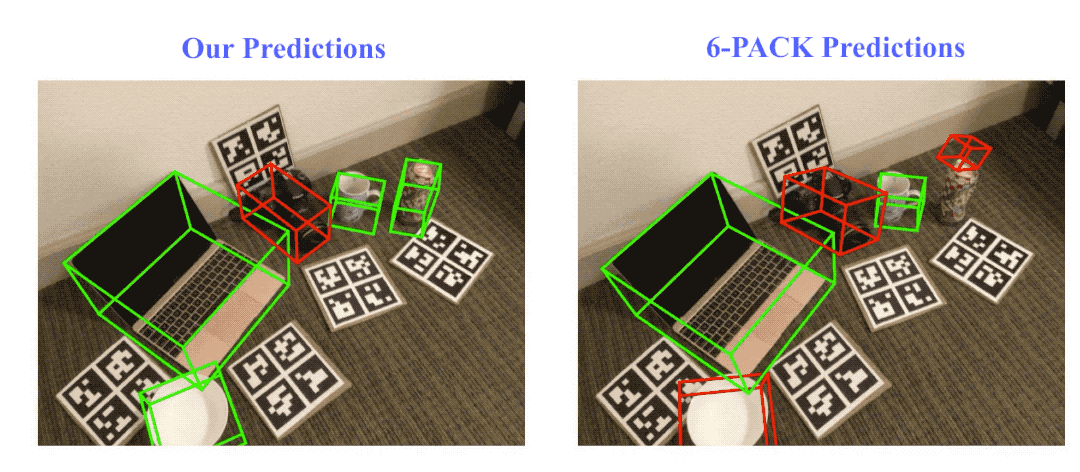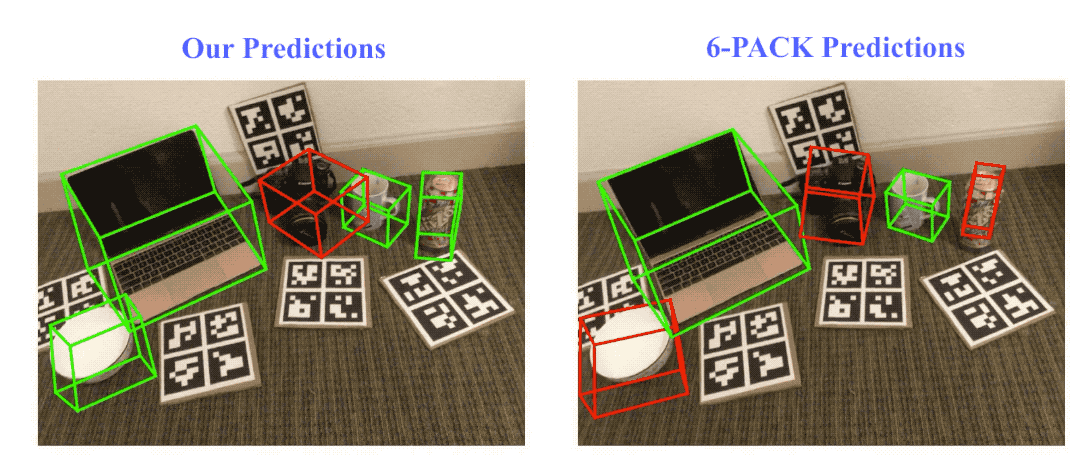
Result visualization on NOCS-REAL275 dataset. Here we compare our method with the state-of-the-art category-level rigid object pose tracking method, 6-PACK. Green bounding boxes indicate on track (pose error ≤ 10º10cm), red ones indicate losing track (pose error > 10º10cm).
Articulated Object Pose Tracking

Result visualization on our SAPIEN articulated object dataset. Green bounding boxes indicate on track (pose error ≤ 3º3cm)

Result visualization on our SAPIEN articulated object dataset. Here we compare our method with the oracle version of the state-of-the-art category-level articulated object pose estimation method, ANCSH, which assumes the availability of ground truth part masks. Green bounding boxes indicate on track (pose error ≤ 3º3cm), red ones indicate losing track (pose error > 3º3cm).





Result visualization on real data. Our models, trained on synthetic data only, can directly generalize to real data, assuming the availability of object masks but not part masks. Left: results on real drawers trajectories we captured, where a Kinova Jaco2 arm interacts with the drawers. Top-right: results on a real scissors trajectory we captured. Bottom-right: Right: results on a laptop trajectory from BMVC dataset.
Paper
Latest version (October 21, 2021): arXiv:2104.03437 in cs.CV.

Team









5 Beijing Institute for General AI 6 Tencent AI Lab
*: equal contribution, †: corresponding author
Bibtex
@inproceedings{weng2021captra,
title={CAPTRA: CAtegory-level Pose Tracking for Rigid and Articulated Objects from Point Clouds},
author={Weng, Yijia and Wang, He and Zhou, Qiang and Qin, Yuzhe and Duan, Yueqi and Fan, Qingnan and Chen, Baoquan and Su, Hao and Guibas, Leonidas J.},
booktitle={Proceedings of the IEEE International Conference on Computer Vision (ICCV)},
month={October},
year={2021},
pages={13209-13218}
}Acknowledgements
This research is supported by a grant from the SAIL-Toyota Center for AI Research, a grant from the Samsung GRO program, NSF grant IIS-1763268, a Vannevar Bush Faculty fellowship, the support of the Stanford UGVR program, and gifts from Kwai and Qualcomm. Toyota Research Institute ("TRI") provided funds to assist the authors with their research but this article solely reflects the opinions and conclusions of its authors and not TRI or any other Toyota entity.
Contact
If you have any questions, please feel free to contact Yijia Weng at yijiaw_at_stanford_edu and He Wang at hewang_at_stanford.edu